


작성일: 2022.07.14 (Thu)
What is VGG16 ?
VGG16은 16개 층으로 이루어진 VGGNet을 의미함
VGGNet (VGG19)는 2014년도 ILSVRC (ImageNet Large Scale Visual Recognition Challenge)에서 준우승한 CNN 네트워크
VGGNet(VGG19)는 사용하기 쉬운 구조와 좋은 성능 덕분에 그 대회에서 우승을 거둔 조금 더 복잡한 형태의 GoogLeNet보다 더 인기 얻었음
VGGNet의 논문 이름은 “Veru deep convolutional networks for large-scale image recognition”로, 네트워크 깊이를 깊게 만드는 것이 성능에 어떤 영향을 미치는지 확인할 수 있음
특징
VGGNet 연구팀은 깊이의 영향만을 최대한 확인하고자 Convolutoin 횟수에 따라 6개의 구조로 나누어 성능을 비교함
결과적으로, Network의 깊이가 깊어질수록 객체 인식 에러가 감소하는 것 확인
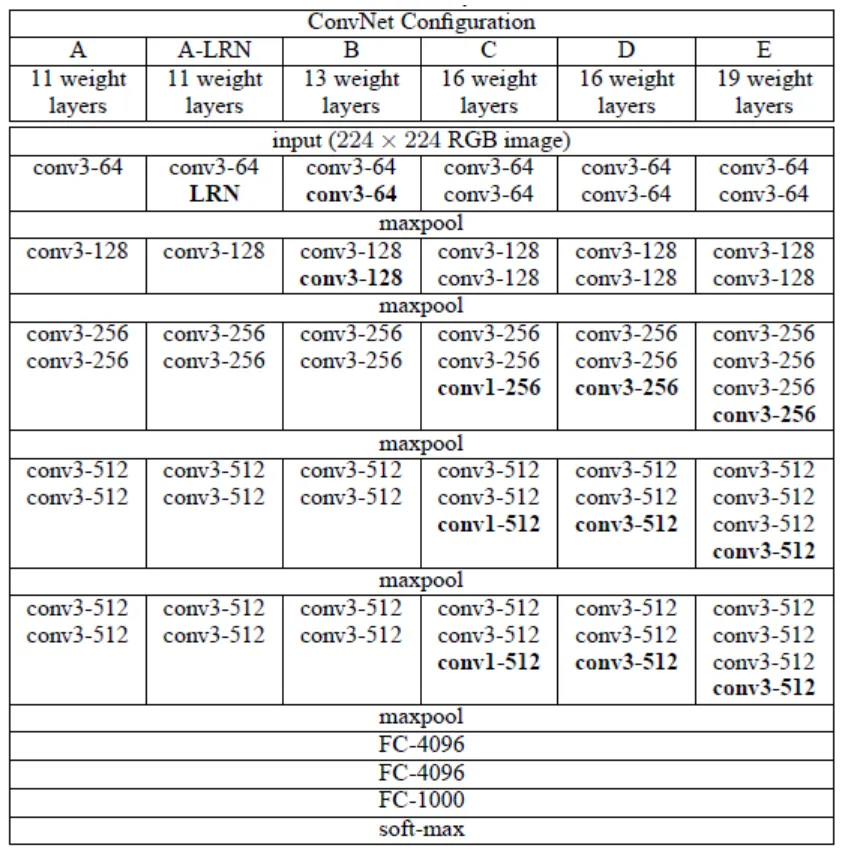
Why 3 x 3 Fliter ?
3 x 3 filter로 2번 convolution 하는 것과 5 x 5 filter로 1번 confolution 하는 것은 동일한 사이즈의 feature map을 나타냄
VGGNet에서 3 x 3 filter를 사용한 이유는, 3 x 3 filter 3개는 총 27개의 가중치를 가지고, 7 x 7 filter는 총 49개의 가중치를 갖기 때문에, 훈련시켜야할 대상의 갯수가 적어져서 학습속도가 향상됨
VGG 모델 이전의 CNN은 비교적 큰 Receptive Field를 갖는 11 x 11 filter 혹은 7 x 7 filter 사용하였음
VGG 모델은 오직 3 x 3 filter을 사용했음에도 이미지 분류 정확도를 비약적으로 개선시킴
VGG16 Structure
VGG16은 13개의 convolution layer와 3개의 fully connected layer로 구성되어 있음
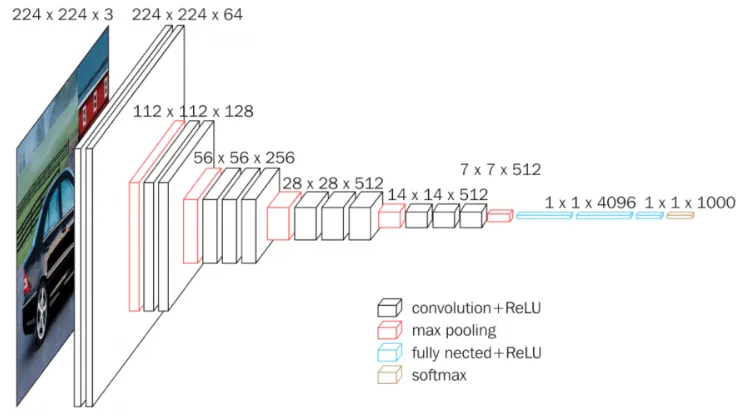
Layer Details
Reference
[1] [CNN] VGG16 블로그
